检索(Crawl)和索引(Index)是SEO领域中非常非常基础的两个概念,是在学习SEO之前一定要理解的基本概念,但检索和索引的优化概念很大,只通过一篇文章我可能没有办法完整的讲完,因此这篇文章我只会针对基础的概念先进行解说。
理解SEO的『检索』以及『索引』
网络爬虫这个说法比较抽象,Google 官方将它称为 Google Spider、Google Bot,可以把整个世界的网络想象为一个巨大蜘蛛网,而搜寻引擎本身有属于它的一只爬虫程序(甚至很多只不同类型的爬虫程序),程序会像蜘蛛一样在这巨大的网络上爬行,并收集信息。
做SEO工作,维护好搜索引擎爬虫与网站之间良好的关系是非常重要的,我们必须要尽量让它能够完整爬取网站上的优质内容,否则会对网站 SEO 有影响,而搜索引擎运作原理我们可以简单分为四个阶段:
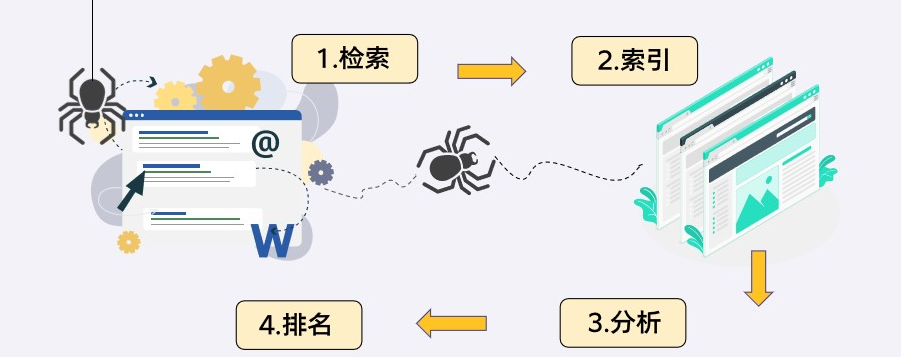
阶段1 – 检索 Crawl(爬取):搜索引擎的爬虫来网站上爬取、下载网站资料的这个动作我们叫做检索,在 Google 官方的文件上正式的专有名词叫做『检索』,但 SEO 业界比较习惯白话一点来称呼,通常我们会称呼为爬取、抓取等比较白话的用词。这个阶段 Google 的爬虫会在网站上爬取所有能爬到的资料,包含网页内容、程序代码、图片等所有的网页信息。
阶段2 – 索引 Index(收录):将网页资料收录、建档到搜索引擎里面的这个动作我们叫做索引(白话一点来说就是收录的意思),但网站就算被收录到搜索引擎里面也不代表会得到很可观的搜索流量,Google 也许愿意收录网站,但未必愿意给网站很好的搜索排名(取决于网站是否是一个优质的网站、是否有被很好的优化,否则 Google 也许愿意收录网站,但不愿意让网站很常被搜索到)
很多人以为网站没有搜索流量就代表没有被 Google 收录,其实这想法是不对的,『是否有被收录』、『是否有排名有流量』是两件事。但至少被 Google 收录进搜索引擎是好的第一步,如果 Google 连收录网站都不愿意,那更不用谈搜索流量以及SEO了。
阶段3 – 分析搜索意图:Google 会透过算法来了解使用者搜索的「关键字」是什么意思?使用者到底需要什么信息?
阶段4 – 曝光在搜索结果:用户搜索查询关键字时,网站可能会被 Google 提供给搜索者,而品牌也会因此获得搜索流量(但这取决于网站是否是一个优质的网站、是否有做SEO)。
为什么学SEO要理解『检索』以及『索引』?
我们在学习 SEO 时,会碰到很多网络上的文章主题都是环绕在所谓的「排名因素」,也就是网站该怎么做,才能被 Google 排名在搜索结果的前面名次,但实际上一个网站会面临到的 SEO 问题有很多,根据网站的架构、网站的行业、所在的市场等不同的因素而定,并不是只要优化「排名因素」就够了,Google如果没办法爬取网站资料,那么网站的排名因素优化做的再好都没用,因为 Google 爬虫根本看不到网站里面的资料,所以要了解搜索引擎的爬虫到底是怎么检索(爬取资料),然后又是怎么索引(收录)网站。
举例来说,在我们常常遇到有客户的网站是使用 AJAX 程序建构出动态式的瀑布流,在进入网站时会看到四则文章连结,接着鼠标向下卷动时,程序则会触发并出现后面四则 (简单来说就是如下图现在的做法 ,俗称瀑布流),
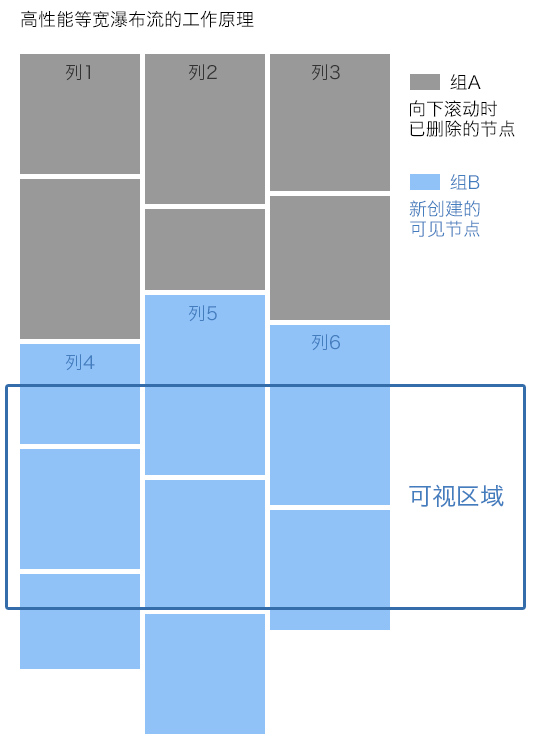
通常这个状况下,Google 爬虫只会爬取到一开始的前面几则文章而已,因为网络爬虫不会像人为使用者去往下卷动、并触发 AJAX 程序的瀑布流。在这类案例之下,Google 爬虫看到的网页信息很少,当然也会影响 SEO(不管网站再棒、再好,只要 Google 爬虫看不到,那么根本没有意义)。
因此做为 SEOer,研究、了解爬虫的效能是很重要的,我们必须要了解搜索引擎的爬虫有哪些效能限制、哪些网页技术是爬虫无法好好的爬取(像瀑布流就是大多情况没办法被搜索爬虫很有效的爬到资料),而Google的爬虫、Bing搜索引擎的爬虫又各自是不同的团队/公司所开发出来,因此它们的爬虫效能又有些不一样,如果做 SEO 时希望除了 Google 之外的 Bing 也可以优化好,那么就要全部都花时间去研究。
如何确定“抓取”或“收录”状况是否有问题?
其实这是个很大的问题,能聊的方面非常多,这篇文章里我们先讲一些基础的。
首先,大部分情况下,只要网站被谷歌“爬取”了,收录就不太会有问题。而如果谷歌抓取了网站却没有收录,那就表示网站可能在用违规或作弊的方法做SEO,从而收到了谷歌的惩罚。
那么,要如何检查谷歌是否准确完整地爬取网站呢?常见的方法之一就是透过 Search Console 的报表(如下图)。
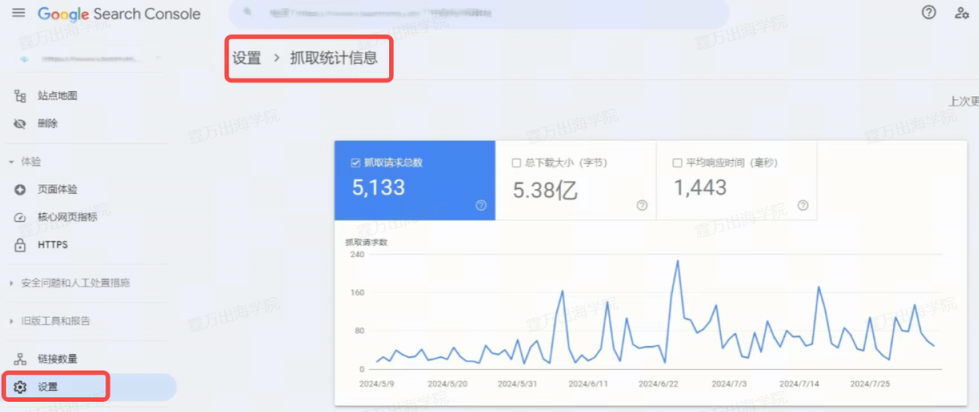
从 Search Console 的“设置>抓取统计信息”中,可以看到每日抓取的网页数目,这个图表可以清晰展现出谷歌每天来爬网站的时候,都爬了多少个网页,一般图表会在一个区间范围内波动。大多数情况下,谷歌每天来爬多少网页取决于三件事情:
- 网站在市场上有多重要、网站的 SEO 权重有多高(也就是所谓的 Crawl Budget)。
- 网站架构是否有使用不利于爬虫的技术,导致爬虫不容易爬到资料。
- 是否有主动阻挡谷歌爬你的网站,比如meta robots、robots.txt。
还有一个要注意的是,如果谷歌爬取网页的数量与网站页面总数相差太大的话,对 SEO 也是不太好的,比方说网站共有 8000 个网页,但谷歌每天只来爬取50页~100页左右,这就不太行了,500~1000 之间才比较正常。
那“收录”呢?要如何检查谷歌是否有效地收录我们的网站呢?
可以从 Search Console 的网页索引编制中,查看谷歌已收录的网页数量,下面也会完整列出哪些网页没被收录、以及发生的原因。
在谷歌SEO上要如何避免“抓取”和“收录”出问题?
排除掉违规、作弊行为而导致谷歌不愿意好好处理网站,我们可以从下面这几点注意优化:
尽量不要对谷歌过度使用不友善的 AJAX,尤其在重要的网页或内容上面。
虽然说谷歌近年来宣称,搜索引擎现在已经能够满有效的解析 JavaScript、AJAX 技术,但实际上还是有很多网站的 JavaScript、AJAX 没办法被谷歌很有效的解析(这篇文章中提到的瀑布流就是 AJAX 的一种应用)。
因此,要尽可能避免在导航栏、面包屑、网站侧边栏、商品/文章列表这些重要的地方使用 JavaScript 以及 AJAX。
尽可能把“网站速度”优化好
根据谷歌官方的说明,谷歌针对每一个网站有所谓的“爬取额度(Crawl Budget)”,也就是说在爬网站时只会给予一定的时间额度,因此必须要尽可能的优化网站速度,让爬虫在固定的时间内可以爬到尽可能多的网站页面,而这个爬取的额度会根据网站在市场上的重要性、以及 SEO 的网站权重而定。
举例来说,谷歌决定每天给网站10分钟的额度,那么每天就只会用10分钟来爬取网站,时间一到它就会自动离开。因此,如果网站速度优化得够好,可以帮助在同样的 10 分钟内爬完网页,简单举例如下:
- 当网站速度很慢时,10分钟只能爬完100个网页。
- 当网站速度够快时,可以在10分钟内爬完500个页面。
避免重复内容发生
重复内容、或者是关键词堆砌问题要尽量避免(尤其是因为网址参数而产生的重复内容),重复内容会让爬虫要去爬更多无效的网页。简单来说,如果网页总共 500 页,但有很严重的重复内容问题而导致网页膨胀到了 1200 页,那么当中有 700 页的网页会浪费掉爬虫的爬取额度,毕竟爬虫每天能爬的网页是很有限的。
最基础的网页问题以及 SEO 问题必须要避免
如果有很多404的网页,或是网站上有很多不必要的内容,可能都会影响爬虫爬网站的效能以及额度,因此在经营网站时一些最基础的事情必须要尽量避免,像是:
- 网页尽量不要有无法访问的情况发生。
- 尽量避免不必要的重定向。
- 如果有产品/文章下架的话,记得把链接从网站上移除,避免消耗掉爬取额度;而且,如果不妥善移除已下架的商品或文章,对网站访问者来说体验也不太好。