厌倦了在 Google Search Console (GSC) 中看到错误“已发现 – 当前未编入索引”?
太多的 SEO 努力都集中在排名上。但是许多网站会从向上查找一个级别 – 索引中受益。
为什么?
因为内容在被编入索引之前无法竞争。
无论选择系统是排名还是检索增强生成 (RAG),内容都无关紧要,除非它被索引。
它出现的地方也是如此——传统的 SERP、AI 生成的 SERP、Discover、Shopping、News、ChatGPT 或任何接下来出现的 AI 。
没有索引,就没有可见性,没有点击,也没有影响。
不幸的是,索引问题非常普遍。
根据我与数百个企业级网站合作的经验,平均 9% 的有价值的深度内容页面(产品、文章、列表等)未能被 Google 和 Bing 编入索引。
那么,如何确保深度内容被索引呢?
第 1 步:审核内容是否存在索引编制问题
在 Google Search Console 和 Bing Webmaster Tools 中,为每种页面类型提交单独的站点地图:
- 一个用于产品。
- 一个用于文章。
- 一个用于视频。
提交站点地图后,它可能需要几天时间才能显示在 Pages 界面中。
使用此界面可以筛选和分析有多少内容被排除在索引之外,更重要的是,还可以分析具体原因。
所有索引编制问题都分为三大类:
糟糕的 SEO 指令
这些问题源于技术失误,例如:
- 被 robots.txt 屏蔽的页面。
- 规范标签不正确。
- Noindex 指令。
- 404 错误。
- 或 301 重定向。
解决方案很简单:从站点地图中删除这些页面。
内容质量低
- 如果提交的页面显示软 404 或内容质量问题,请首先确保所有与 SEO 相关的内容都在服务器端呈现。
- 确认后,专注于提高内容的价值——增强页面的深度、相关性和唯一性。
处理问题
这些更复杂,通常会导致诸如“已发现 – 当前未编入索引”或“已爬网 – 当前未编入索引”之类的排除项。
虽然前两类问题通常可以相对较快地解决,但处理问题需要更多的时间和精力。通过使用站点地图索引数据作为基准,可以跟踪提高网站索引编制性能的进度。
第 2 步:提交新闻站点地图以更快地索引文章
要在 Google 中将文章编入索引,请务必提交 News 站点地图。
此专用站点地图包含特定标签,旨在加快对过去 48 小时内发布的文章的索引。
重要的是内容不需要传统上是 “新闻” 即可从这种提交方法中受益。
第 3 步:使用 Google Merchant Center Feed 改进商品索引编制
虽然这仅适用于 Google 和特定类别,但将商品提交到 Google Merchant Center 可以显著改善索引。
确保整个在售商品目录已添加并保持最新状态。
第 4 步:提交 RSS 提要以加快抓取速度
创建一个 RSS 源,其中包含过去 48 小时内发布的内容。
在 Google Search Console 和 Bing Webmaster Tools 的站点地图部分提交此提要。
这很有效,因为 RSS 源本质上比传统的 XML 站点地图更频繁地被抓取。
此外,索引器仍然响应 RSS 源的 WebSub ping,XML 站点地图不再支持这种协议。
为了最大化收益,请确保开发团队集成了 WebSub。
第 5 步:利用索引 API 加快发现速度
集成 IndexNow(无限制)和 Google Indexing API(每天限制为 200 次 API 调用,除非可以确保增加配额)。
第 6 步:加强内部链接以增强索引信号
大多数索引器发现内容的主要方式是通过链接。
具有更强链接信号的 URL 在抓取队列中的优先级较高,并具有更多的索引功能。
虽然外部链接很有价值,但内部链接是真正改变规则的因素,可以索引具有数千个深度内容页面的大型网站。
相关内容块、分页、面包屑,尤其是主页上显示的链接是 Googlebot 和 Bingbot 的主要优化点。
当涉及到主页时,无法链接每个深度内容页面 – 但不需要这样做。
重点关注尚未编入索引的那些。方法如下:
- 发布新 URL 时,请对照日志文件检查该 URL。
- 当第一次看到 Googlebot 抓取 URL 时,请立即 ping Google Search Console Inspection API。
- 如果响应是“URL is unknown to Google”、“Crawled, not indexed”或“Discovered, not indexed”,请将 URL 添加到填充主页部分的专用 Feed。
- 定期重新检查 URL。编入索引后,将其从主页 Feed 中删除,以保持相关性并专注于其他未编入索引的内容。
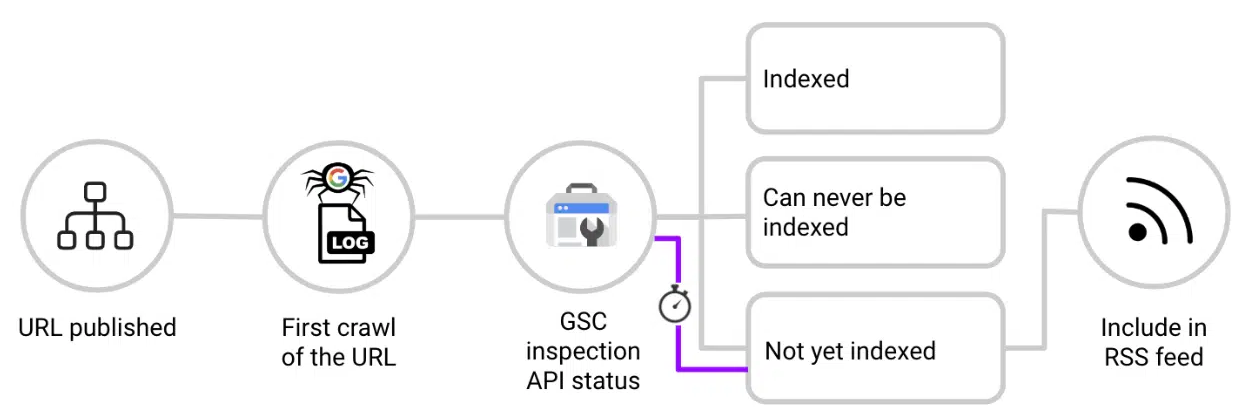
这有效地创建了从主页链接的非索引内容的实时 RSS 源,并利用其权限来加速索引。
第 7 步:阻止来自爬虫的非 SEO 相关 URL
定期审核日志文件,并使用 robots.txt 禁止阻止高爬取、无价值的 URL 路径。
分面导航、搜索结果页面、跟踪参数和其它不相关内容等页面可以:
- 分散爬行者的注意力。
- 创建重复内容。
- 拆分排名信号。
- 最终降级索引器对网站质量的看法。
但是,仅robots.txt不允许是不够的。
如果这些页面有内部链接、流量或其它排名信号,索引器仍然可以将它们编入索引。
要防止这种情况:
- 除了在 robots.txt 中禁止路由外,还将 rel=“nofollow” 应用于指向这些页面的所有可能链接。
- 确保不仅在现场完成此作,而且在事务性电子邮件和其它渠道中执行此作,以防止索引器发现 URL。
第 8 步:使用 304 响应帮助爬虫确定新内容的优先级
对于大多数网站,大部分爬网都投入到刷新已编入索引的内容上。
当站点返回 200 响应代码时,索引器会重新下载内容并将其与现有缓存进行比较。
虽然这在内容更改时很有价值,但对于大多数页面来说不是必需的。
对于尚未更新的内容,返回 304 HTTP 响应代码(“未修改”)。
这会告诉爬网程序页面没有更改,从而允许索引器将资源分配给内容发现。
第 9 步:手动请求将难以编入索引的网页编入索引
对于仍未编入索引的顽固 URL,请在 Google Search Console 中手动提交它们。
但是,请记住,每天最多提交 10 次,因此请明智地使用它们。
根据我的测试,与通过 IndexNow API 提交相比,在 Bing Webmaster Tools 中手动提交没有明显优势。
因此,使用 API 的效率更高。
最大限度地提高网站在 Google 和 Bing 中的可见度
如果内容没有被索引,它就是不可见的。不要让有价值的页面处于不确定状态。确定与内容类型相关的步骤的优先级,采取主动方法编制索引,并释放内容的全部潜力。