提问:
当你进入一个景点浏览时,有的地方有指示牌提示此景点暂停开放,你会怎么办?
你可能会绕过此地继续浏览。
你也可能会想办法偷偷溜进去。
网站提示搜索引擎机器人访问网站的指示牌是robots.txt。
robots.txt的介绍
robots.txt是一个纯文本文件,用于声明该网站中不想被robots访问的部分,或者指定搜索引擎蜘蛛只抓取指定的内容。
robots.txt不是规定,而是约定俗成需要搜索引擎蜘蛛自觉遵守一种道德习俗。
当一个搜索引擎蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt。
如果找到,搜索引擎蜘蛛就会按照该文件中的内容来确定抓取的范围。
如果该文件不存,那么搜索引擎机器人就沿着链接抓取。
robots.txt的作用
1、防止私密或重要内容被搜索引擎抓取
如:网站在线留言信息、email信息、网站后台等私密内容被搜索引擎蜘蛛访问抓取可能给企业带来灾难性的损失。
robots.txt可以限制搜索引擎抓取重要内容避免以上的情况发生。
大型网站特别注意,小型网站也要注意保密等工作。
2、节省服务器资源,从而提高服务质量
如:搜索引擎蜘蛛爬行次数过多会造成服务器资源大量消耗,不仅浪费流量还可能降低了用户体验,通过robots.txt可以控制搜索引擎蜘蛛的爬行时间间隔等避免以上情况的发生。
一般大型网站可能会面临这种问题。
3、减少重复抓取,提高网站质量
网站内可能存在页面内容相似甚至相同的页面,用robots.txt限制搜索引擎抓取,可以避免搜索引擎人为网站内存在大量重复性页面从而降低整个网站的权重的做法。
4、指定sitemap文件位置
robots.txt可以指定sitemap的位置,方便搜索引擎的爬行,从而实现站内页面的收录更友好。
大小网站都适合。
robots.txt的语法(写法可参考任意文章)
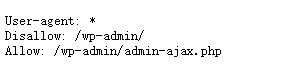
robots.txt的用法
robots.txt必须放置在一个站点的根目录下,而且文件名必须全部小写。
一般情况allow和allow同时使用。
提问:如果搜索引擎已经收录页面,而这个网页是我们不想让搜索引擎收录的页面,应该做?
robots.txt不能删除搜索引擎中已收录的页面。
robots meta标签可以解决这个问题。
提问:考虑下robots.txt不太擅长管理什么样的页面?
robots.txt不太擅长管理单个页面
robots.txt的禁止抓取设定是基于目录或某一类网页的,robots.txt不善于管理单个页面。
会暴露重要页面地址,存在安全隐患。
robots meta标签可以解决这个问题。
robots meta标签介绍
robots.txt文件主要是限制整个站点或者目录的搜索引擎访问情况,而robots meta标签则主要是针对某个具体的页面,robots meta标签是放在页面中,专门用来告诉搜索引擎蜘蛛如何抓取该页的内容。
<meta name=”robots” content=”index,follow”>
robots meta标签语法
robots meta标签中,name=”robots”表示所有的搜索引擎,可以针对某个具体搜索引擎写为:name=”Baiduspider”。content部分有四个指令选项:index,noindex,follow,nofollow指令间以”,”英文逗号分隔(大小写无要求,但建议小写)
index指令告诉搜索机器人可以抓取该页面。
follow指令表示搜索机器人可以爬行该页面上的链接继续爬下去。
共有四种组合:
<meta name=”robots” content=”index,follow”>
<meta name=”robots” content=”noindex,follow”>
<meta name=”robots” content=”index,nofollow”>
<meta name=”robots” content=”noindex,nofollow”>
特殊写法:
<meta name=”robots” content=”index,follow”>可以写成<meta name=”robots” content=”all”>。
<meta name=”robots” content=”noindex,nofollow”>可以写成<meta name=”robots” content=”none”>。
robots meta标签的注意事项
要注意的是:上述的robots.txt和robots meta标签限制搜索引擎机器人(robots)抓取站点内容的办法只是一种规则,需要搜索引擎蜘蛛的配合才行,绝大多数的搜索引擎机器人都遵守此规则,但并不是每个搜索引擎蜘蛛都遵守。
提问:
不允许任何搜索引擎蜘蛛抓取此网页,且不允许任何搜索引擎蜘蛛能从本页面继续爬下去。
<meta name=”robots” content=”noindex,nofollow”>